


OCR stands for optical character recognition. OCR is the technology that allows converting images into editable searchable text. PDF Text OCR Xtractor does precisely that: It converts PDF documents and photos of text into editable text. The software is an enhanced shell for the TESSERACT OCR Engine, the most advanced OCR engine on the market, with a long story in detail below in this article. The program creates an enhanced shell over the TESSERACT OCE engine because it intelligently scales up by a zoom factor the original image so that the document becomes better visible to the OCR engine, something other OCR software products do not perform. PDF OCR Text Xtractor reaches 96% accuracy, becoming a great application in its category.
What is the TESSERACT OCR Engine?
Tesseract is an OCR engine used on different operating systems. The technology is free binding to the terms of the Apache License. Created by Hewlett-Packard in the 80s as proprietary, it became open source in 2005 and passed on to Google ever since 2006. Tesseract is considered one of the most accurate OCR engines in existence.
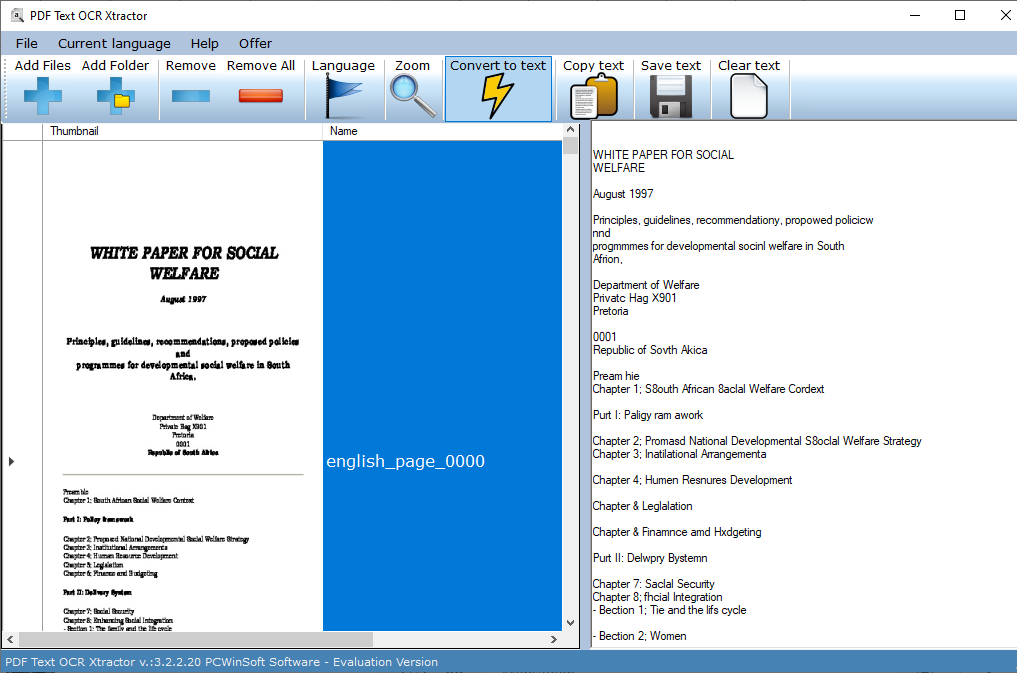
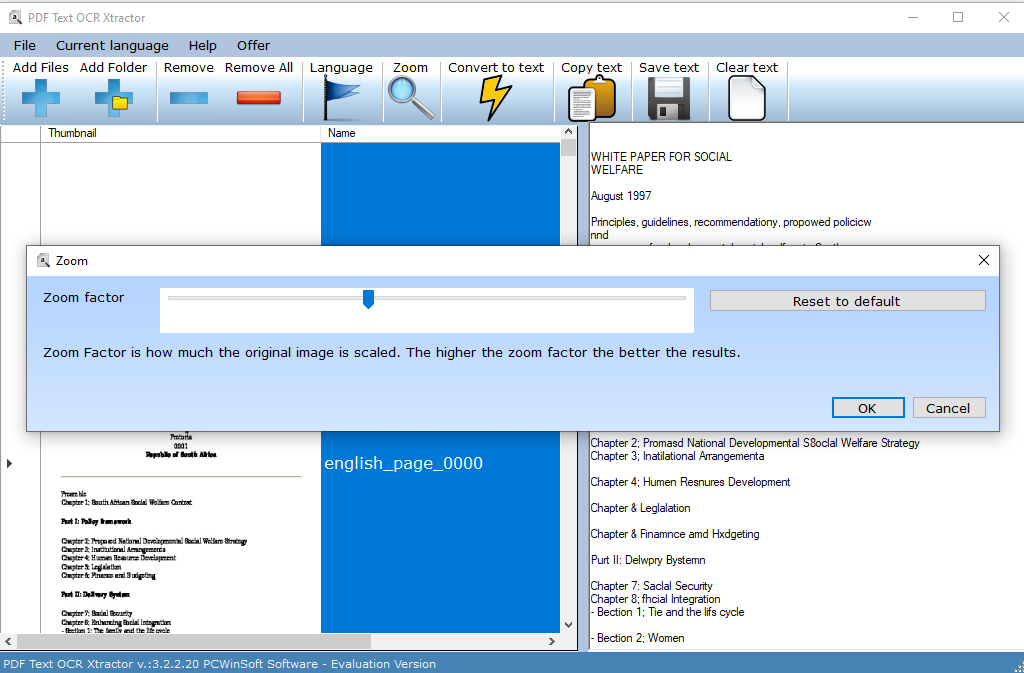
Below are a couple of screenshots of the PDF OCR Text Xtractor user interface. Observe the screenshot at the right of the so-called zoom factor. It dramatically enhances the vision of the OCR engine, which in turn generates much more outstanding results than the competitors of the program on the market.
More than 23 languages
PDF Text OCR Xtractor supports more than 23 different languages; therefore, no matter which country you are from, this excellent piece of software can greatly value you. The software includes the languages of all economically prominent countries and a vast list o others.
Putting a telescope to look at your documents
PDF Text OCR Xtractor is the only software on the market to come up with the concept of zoom meaning to put the amplifying lens on top of the documents so that the OCR engine can see it much better thus generating excellent outstanding results that you can not obtain using other products. It is a simple concept, but this piece of software is the first to actually have this feature.
PDF Text OCR Xtractor supports PDF files giving it a greater purpose because PDF is distributed locked so that the text can only be read, not edited.
PDF Tet OCR Xtractor, as the name already says, supports PDF files. One of the purposes of PDF files is to be distributed locked so they can not be edited. This piece of software overcomes this security feature and can turn what you can only read into editable searchable text.
With the support of over twenty different languages, you can turn any locked PDF document into text that you can copy, paste, edit, and reassemble some other way. The program gives you incredible power. Note that the software also supports PNG files, JPG, GIF, BMP, and most image formats commonly known.
Up to 96% accuracy on text recognition
While the great majority of programs OCR for text recognition achieve a maximum of 82 to 84% accuracy, PDF Text OCR Xtractor reaches up to 96% accuracy due to its zoom feature. This number is remarkable in the market, and it is unparalleled in its competition. If you have up to 8GB RAM memory, then you can take the zoom factor to the limit, which is 2000 times the original size of the document and accuracy gets even higher. There are no regrets in the minds of users who acquire this powerful gadget.
Conclusion
Unequivocally you can not go wrong with PDF Text OCR Xtractor. It is the software with the higher levels of accuracy and you can’t ask for anything better, plus it supports PDF which gives the user a lot of optical character recognition power to transform locked-up read-only documents and images into editable and searchable text. Two thumbs up for this OCR tool: The best in accuracy we found by searching the OCR market trespassing even giants of the software industry.